
























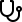







服务优势
-

多元算力
多种高性能NVIDIA算力卡,易用稳定,强力支撑您的训练、微调、推理等服务,后续将扩展更多国产算力卡 -

绿色算力
采用包括绿电、光伏、液冷多种低碳节能技术,实现算力资源的绿色可持续发展 -

稳定性能
自有机房,多重容灾。电力、网络设计、建造均按照国家A级数据中心标准执行;可用率达99.9% -

数据安全
配备多重安全防护设备,以防止数据泄露、篡改等
产品与功能介绍
FP32
82.58TFLOPS
FP16
165.2Tensor TFLOPS
消费显卡之王
基于Ada Lovelace架构,由于高性能和高图形处理能力,备受图形渲染和高性能计算需求开发者的青睐
-
24
GB24GB显存
超大显存数据检索和存储,高效处理大量数据和模型参数,避免频繁数据传输和存储延迟的干扰 -

应用场景
高端游戏、视频编辑与渲染、模型推理任务
FP32
19.5TFLOPS
FP16
312Tensor TFLOPS
AI训练旗舰产品
基于Ampere架构,提供20倍性能提升,专为高性能AI训练和推理设计企业级功能支持
-
80
GB80GB高宽带显存
适合处理大型数据集和复杂模型;多实例GPU (MIG) 和NVLink技术,实现资源优化和高速GPU通信卓越的AI计算性能 -
应用场景
深度学习训练与推理、高性能计算
FP32
67TFLOPS
FP16
989Tensor TFLOPS
变革AI训练
基于Hopper架构,与上一代产品相比,可为多专家 (MoE) 模型提供高 9 倍的训练速度。极高的Tensor算力和内存带宽,使其在深度学习和科学计算领域无可匹敌
-
24
GB高速互联
通过最新的NVLink和NVSwitch技术,无论是机内还是机间都有着极高的互联带宽,可以构建大规模算力集群,为小型企业到大规模统一GPU集群提供高效的可扩展性 -
应用场景
大模型模型训练
算力市场、模型市场、镜像市场
提供灵活多样、安全稳定、统一调度的算力资源。可用于人工智能训练、科学计算等不同的应用领域。助推算力向用户端延伸,健全算力产业链。





灵活的算力资源服务降低算力成本
-

按量使用
支持单卡,多卡模式,按时计费,灵活应对各种需求 -

整机包月
长期使用更省心,随时随地便捷使用,避免队列等待 -

灵活调用
云端海量镜像、大模型资源,支持自有数据上传
光环云自研云算通智能算力调度平台
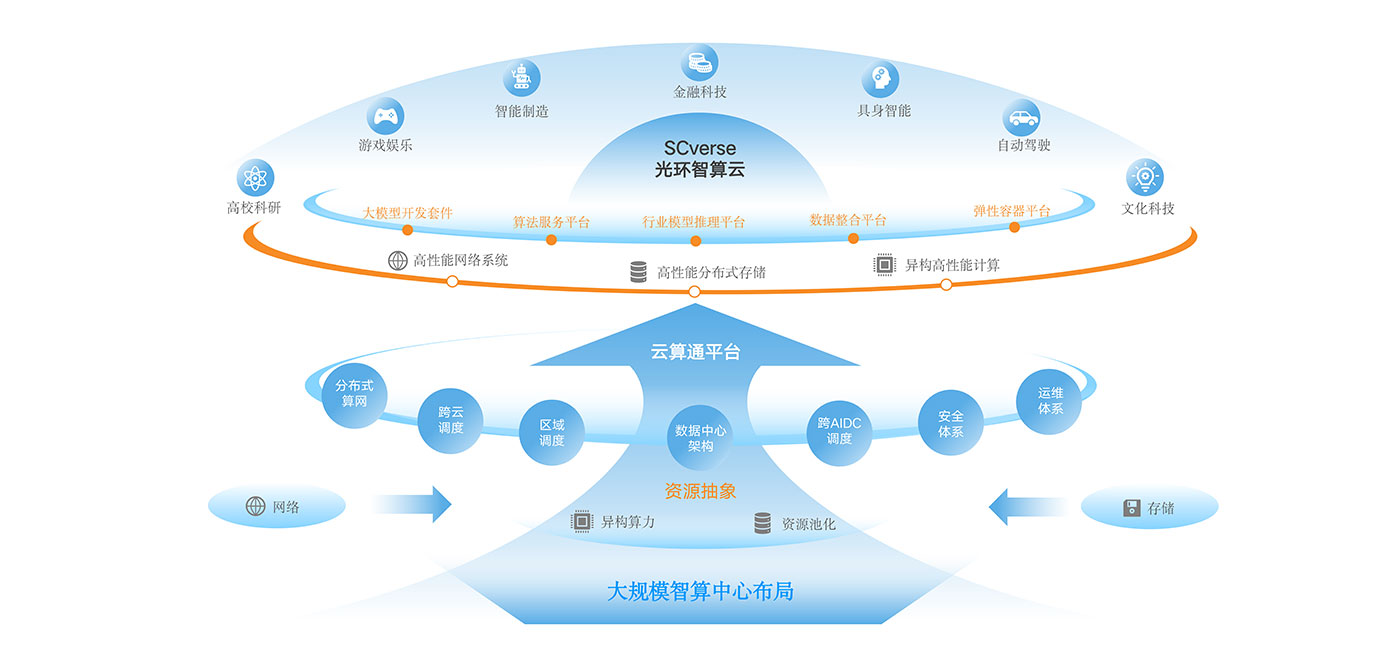
算力AI调度平台
算力AI调度平台是一个综合性的服务平台,专注于算力资源的集中管理与提供。一站式算力服务,涵盖运维调度、买卖,支持AI大模型应用的推理、训练及优化特色四个一键功能:模型推理部署、模型训练微调、算力资源申请、应用发布
多元异构AI平台
-

灵活
-

延时低
-

高算力
-

多元结构
-
弹性
-

潮汐需求
平台能力
-

算力中心的设备纳管和资源分配
-

用容器化与调度引擎提升资源使用率
-

国产化硬件的适配和性能提升
-

数据湖和数据资产管理
一键部署模型推理服务
-
支持多资源池推理部署
-
支持按小时、包年包月计费方式
-
支持裸金属+容器部署方式
-
预制海量公共模型
-
支持个人工具上传,并部署
-
支持远程镜像仓库,Dockerhub、阿里云、华为云镜像仓库,满足跨平台模型部署
算力运营管理中心
-
产品重组合编排能力
-
多样化计量
-
多样化计量
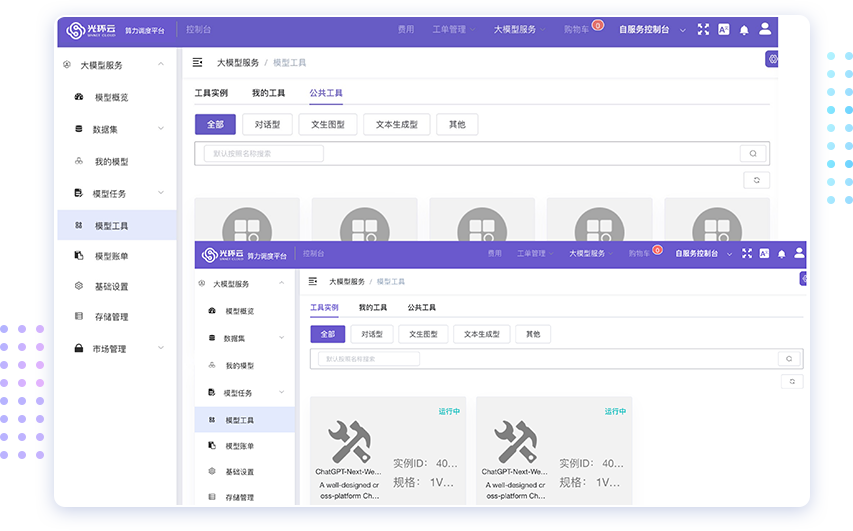
一站式应用超市
-
均可执行一键化部署
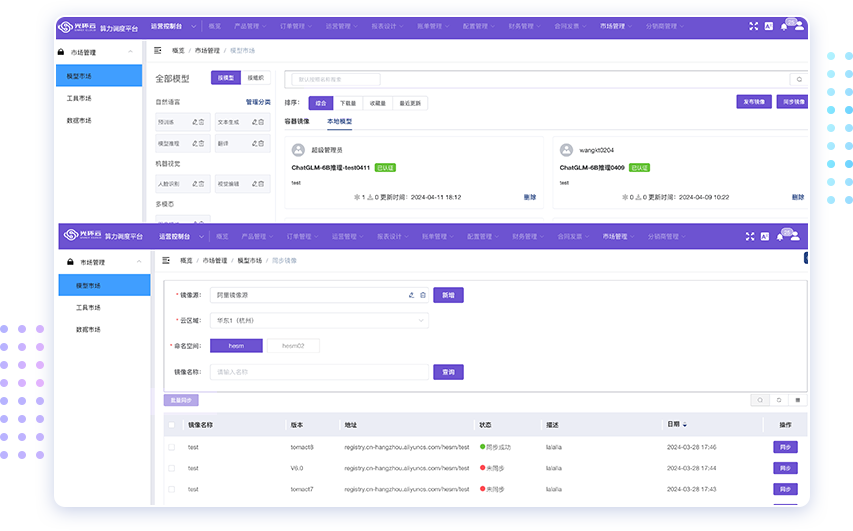
一体化监控管理
-
算力服务
-
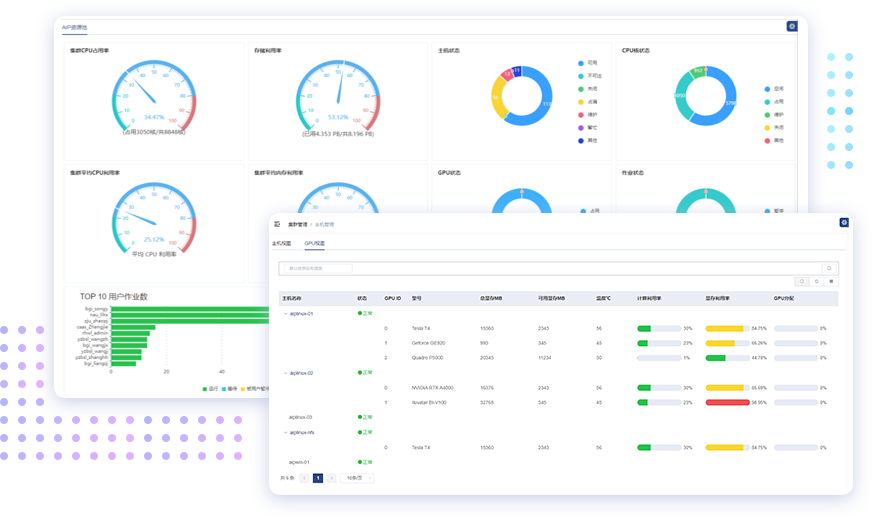
可视监控
-
一体化监控
终端客户多种付费方式
-
在线充值
-
分配预算
-
授信+容器部署方式

 京公网安备11010102003447号
京公网安备11010102003447号